-

大科技 现有杂志2元一本打包处理中
两元一本全新杂志清仓处理所有的书都是全新杂志,不是二手杂志,这些书以后不会再有,全都是绝版! 购买方式:请加我们微信13907547665 扫描本二维码加好友 &nbs...
-

浅析蚕桑技术推广工作中存在的不足点及对策
浅析蚕桑技术推广工作中存在的不足点及对策 郭宏铭 (夷陵区农业技术推广中心三斗坪镇分中心 湖北宜昌 443134) 摘要:桑蚕产业具有悠大的历史,随着科...
-

-

天摧地崩:探秘全球最极端的天气现象
近一两年,你有没有发现夏天热到必须开空调,冬天冷到无法出门?气温超过正常范围的天气属于极端天气,极端天气一直存在,只是过去不如现在这么频繁。除了难以忍受的气温,人类还曾经历过大得离谱的降雨、降雪、风暴等,一起来看看吧。...
-

理解宇宙?这些数是钥匙
物理学中的那些常数 在你心目中,物理学规律是什么样子的呢?它们都是一些干巴巴的公式或方程,对吧,比如浮力定律、牛顿第二定律、万有引力定律、欧姆定律等等。在公式里,一些是代表物理量的符号,另一些则是不变的常数。比如万有引力定...
-
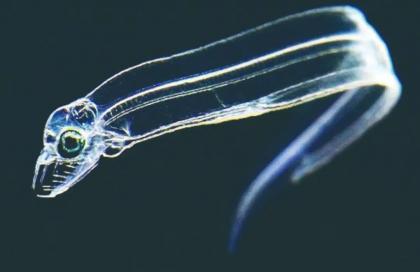
谜之透明鱼原来是老朋友
海洋中有一种透明鱼,看不到内部身体器官,头小小,身体薄薄,长着长牙,看起来非常罕见,却是餐桌上常见的美食。 没有鱼肉的鱼 科学家曾在海里发现了一种透明鱼,它们形状...
-

气鼓鼓的动物有何特殊之处?
一些小朋友生气的时候会皱起眉头,鼓起腮帮子,脸蛋像个充气的气球。自然界中一些动物同样能让身上某些部位充气鼓起来,难道它们也生气了吗?一起来看看这些气鼓鼓的动物。 充气麦克风...
-

抢抓高质量发展先机,赋能企业数字化转型升级 ——北京煊禾科技有限公司总经理郑丽敏专访
抢抓高质量发展先机,赋能企业数字化转型升级 ——北京煊禾科技有限公司总经理郑丽敏专访 宋宏科/文 近年来,受到全球新...
-
人工智能时代下的临床麻醉,你了解哪些?
人工智能时代下的临床麻醉,你了解哪些? 谢志高 如今,随着大型临床数据库愈来愈丰富,人工智能在医学领域中得到了快速应用和发展,计算机能够模拟临床医师的思维,利用机器学习并处理复杂的临...
-

被死神“厌恶”的传奇宇航员——阿列克谢·列昂诺夫
在我们的印象中,宇航员是一个高危行业,特别是人类刚开始进行太空探索时,那时经验和技术的不足导致许多宇航员丧命。但是,有这样一个宇航员,他曾数次从死神的魔爪中逃生,克服了简陋的设备造成的危机,为人类的航天事业做出了巨大贡献,他就是苏...
-

